
This model shows what happens when you try to violate some of the location restrictions that the reliability element has, and how you can work within those restrictions to create the model you need.
In this model, the Parent element is dependent on a child element called Child.
The first restriction is that you cannot directly reference the child element of a peer (note that you are not restricted from referencing a peer element whose logic tree references its child elements). Open the Function_Problem_1 element's dialog and create a new RL node attached to the External Requirements node. Browse to the element called Child inside the Parent element. You will receive an error message, saying that you are prohibited from referencing this element.
In order to create the link, the Child element must be a peer of both the Function element and the Parent element. This is shown in the Solution_Problem_1 container. Note that there is no restriction on referencing an element whose logic tree includes references to child elements. For example, in the main level of the model, you could create an External Requirements node that references the Parent element directly.
The second restriction is that two components cannot be mutually dependent on each other in order to operate. Create an External Requirements RL node in the Parent element that references the Function_Problem_2 element and then try to create an External Requirements RL node from the Function_Problem_2 element to the Parent element. GoldSim will tell you that this is an invalid reference and prevent you from running the model.
To get around this, one of the elements must be placed as the child element of the other, with an Internal Requirements reference to the element placed as a child. In this way, the element placed as a child must be operable in order for the parent to function, but the child cannot operate until the parent is operational. This is shown in the Solution_Problem_2 container.
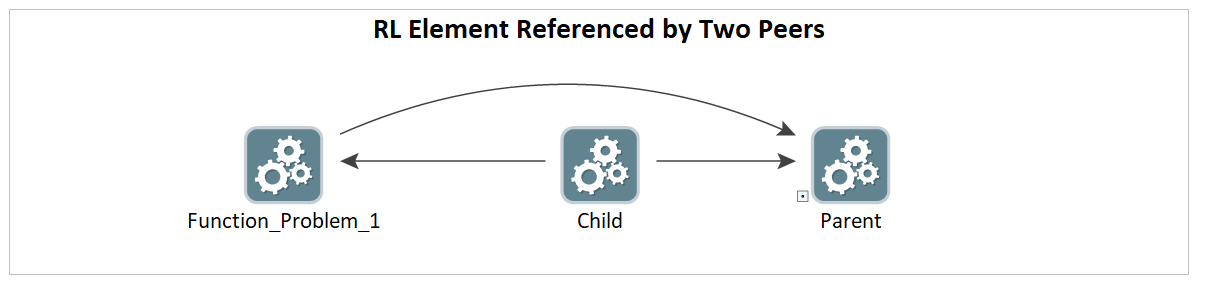
RL Element Referenced by Two Peers
As mentioned in the top level of the model, in order for an element to be referenced by two peers, the Child element must be a peer of both the Function element and the Parent element.
Mutually Dependent Elements
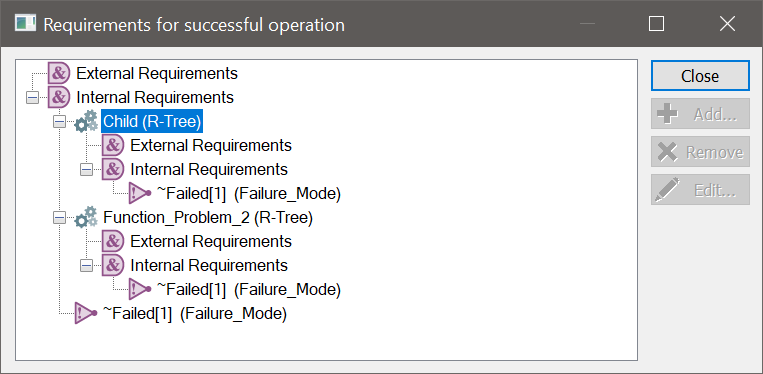
As mentioned in the top level of the model, two mutually dependent elements cannot be peers. One of the elements must be placed as a child element, and referenced by the parent element as an Internal Requirement.
In this way, the element placed as a child cannot operate unless its parent is operating (as it is a child), and conversely, the parent element is unable to operate unless the element placed as a child is operable, as it is one of the parent component's internal requirements.

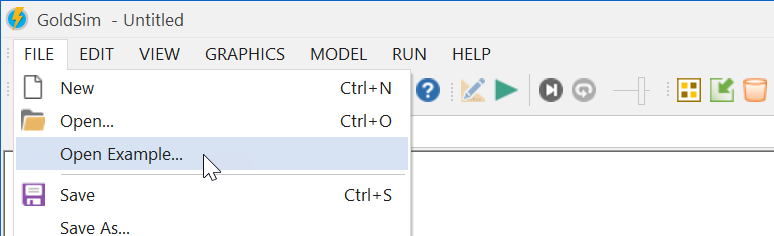
To Open the Model File:
- Start GoldSim
- Click on the File and select Open Example...
- Browse to Reliability Examples
- Select the file called InternalExternalRestrictions.gsm
Comments
0 comments
Please sign in to leave a comment.