Introduction
In GoldSim version 11.1.5, an improved Monte Carlo Latin Hypercube Sampling (LHS) algorithm was implemented to minimize correlation within non-scalar Stochastic elements. The change does not impact scalar Stochastic sampling or sampling of non-scalar Stochastics with LHS turned off. In other words, for a given seed, sampled results should be identical between versions 11.1.4 and 11.1.5 for scalar Stochastic elements and for non-scalar Stochastic elements with LHS turned off. With this change, note that for a given seed and with LHS turned on, only the sampled result of the first array item of a non-scalar Stochastic element will be the same when comparing versions 11.1.4 and 11.1.5.
This article first provides some basic background information about Latin Hypercube Sampling before describing limitations of the old implementation (in versions 11.1.4 and earlier) and how correlation within non-scalar Stochastic elements could occur. Then, LH sampling results from version 11.1.5 are shown to illustrate the improvement in the algorithm.
Background on Latin Hypercube Sampling
In GoldSim, Latin Hypercube Sampling is enabled by default in the Monte Carlo settings. LHS is used to ensure that the entire space of a stochastic parameter is well sampled, even in situations where relatively few Monte Carlo realizations are used. To do this, the distribution function of a stochastic parameter is divided into equal probability strata and then a value is sampled from each of the strata in random order. The number of strata is equal to the number of realizations, up to a maximum of 10,000 strata.
For illustration, take the simple case of a uniform 0 to 1 Stochastic element in a model with 5 realizations. Values are sampled in random order from the following 5 equal probability strata of the uniform distribution: 0 to 0.2, 0.2 to 0.4, 0.4 to 0.6, 0.6 to 0.8 and 0.8 to 1.0. Shown below are actual sampled results from a GoldSim model.
Note that for each random seed (i.e. each column) there is always a value from each of the 5 strata. Highlighted in gray are values sampled from the 0.6 to 0.8 stratum. If the strata are numbered in increasing order (e.g. 0 to 0.2 is stratum 1, 0.2 to 0.4 is stratum 2 and so on to 0.8 to 1.0, which is stratum 5), then it can be seen for seed 1 that the sampling order was 1, 5, 3, 4, 2; The sampling order for seed 2 was 4, 2, 5, 3, 1 and the sampling order for seed 3 was 5, 3, 2, 1, 4.
Latin Hypercube Sampling in Versions 11.1.4 and Earlier
LH sampling results shown in the previous section are for a scalar Stochastic element. Whether the model (used to generate the results above) is run in 11.1.4 or 11.1.5, results are identical. For non-scalar Stochastics, however, sampled results are different between the two versions. Take, for example, a 3-item vector Stochastic sampled over 5 realizations. In version 11.1.4, results are like those shown below. The colors correspond to the 5 different strata.
The order in which the strata are sampled for the first array item, V[1], is 1, 5, 3, 4, 2. Note that the order for the subsequent columns (corresponding to array items V[2] and V[3]) are the same, but simply shifted by one position relative to the previous column. So the order for V[2] is 5, 3, 4, 2, 1 and the order for V[3] is 3, 4, 2, 1, 5. The old LHS implementation only generates a single randomized sequence for sampling the strata. It reuses this same sequence for every item of the non-scalar Stochastic, just shifting the starting stratum by one for each array item. A pattern, as shown in the results above, is generated as a consequence.
Another consequence of the old LHS implementation can be seen when the size of the array is greater than the number of realizations. In the example below, the results are for a 6-item vector. As explained already, values are only sampled from 5 different strata since there are 5 realizations in the model. For any given realization, values for array items V[1] through V[5] are sampled from the 5 different strata in random order. Thereafter, starting with array item V[6], the strata are again sampled in the same random order.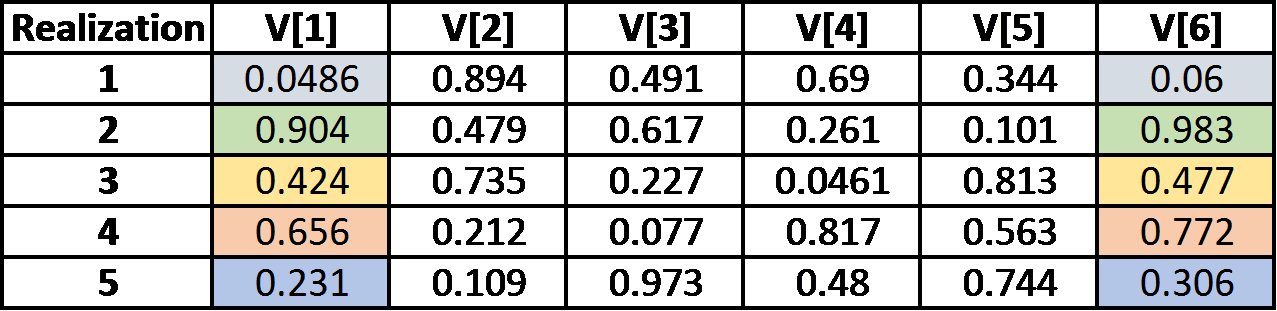
A consequence of this is that V[1], V[6], V[11], ... are sampled from the same stratum, V[2], V[7], V[12], ... are sampled from the same stratum, and so on. As a result, there is very high correlation between items within an array. This can be seen dramatically in a scatter plot. Below is a scatter plot of the values of V[1] and V[6] from the table above. The correlation value is 0.997.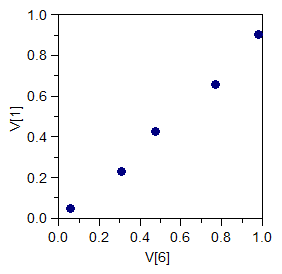
Improved LHS Results in GoldSim Version 11.1.5
As stated previously, the old LHS implementation only generates (for a given Stochastic element) a single randomized sequence for sampling the strata. It then reuses this same sequence for every item of a non-scalar Stochastic, just shifting the starting stratum by one for each array item.
In the new LHS implementation (starting in GoldSim version 11.1.5) a different seed is used for each individual array item of a non-scalar Stochastic. As a result, the order in which strata are sampled is different for each array item. This eliminates the correlation seen in the examples above. Below are the results generated in version 11.1.5 for the same 3-item vector Stochastic for which version 11.1.4 results are shown in the previous section.
Below are the results generated in version 11.1.5 for the same 6-item vector Stochastic for which 11.1.4 results are shown in the previous section.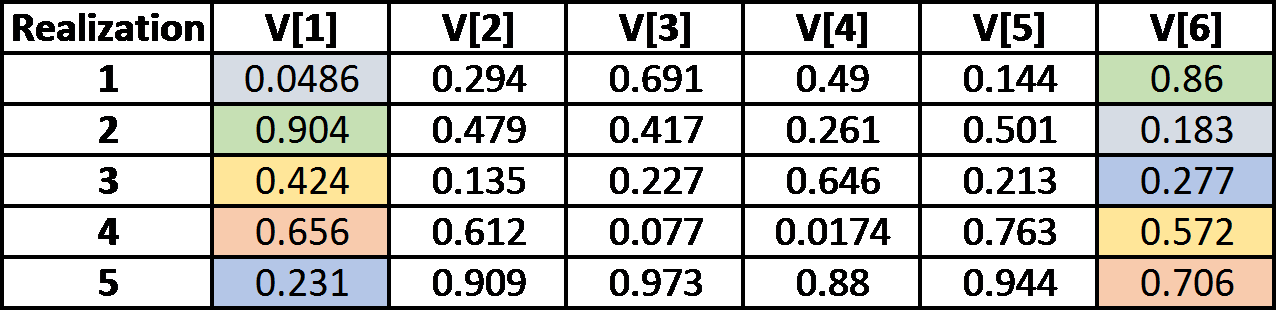
Comparison of Distributions of Correlations
It is clear from this simple example that the LHS implementation in version 11.1.5 at least eliminates the patterns seen previously in the version 11.1.4 results. However, the best gauge to evaluate how well the new implementation generates independent, random values for non-scalar Stochastic elements is to compare the distribution of correlations between array items.
Sampled results of a 50-item vector stochastic were generated for 20, 40 and 100 realizations. Then, correlation results were copied from a multivariate result element into Lookup Tables and analyzed. By running the model for 1225 realizations, referencing a different correlation value from the tables on each realization, it was possible to generate result distributions of the correlation values.
Distributions of correlation values generated in version 11.1.4 for 20, 40 and 100 realizations are shown below.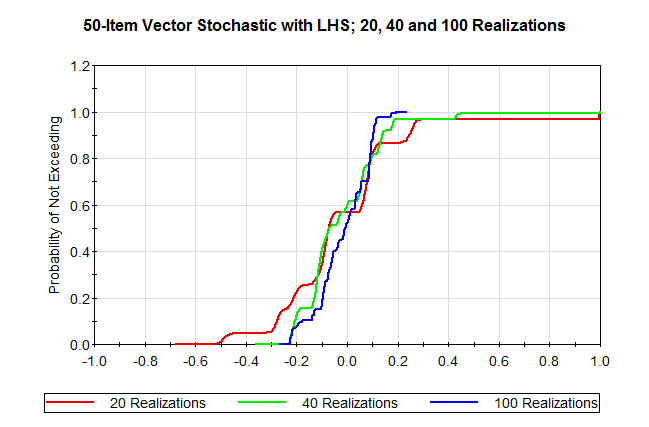
Distributions of correlation values generated in version 11.1.5 for 20, 40 and 100 realizations are shown below. In contrast to the 11.1.4 results, which are irregularly distributed, the results in 11.1.5 are much more smoothly distributed. Distributions are centered at 0 and the spread in the distributions decreases with increasing number of realizations.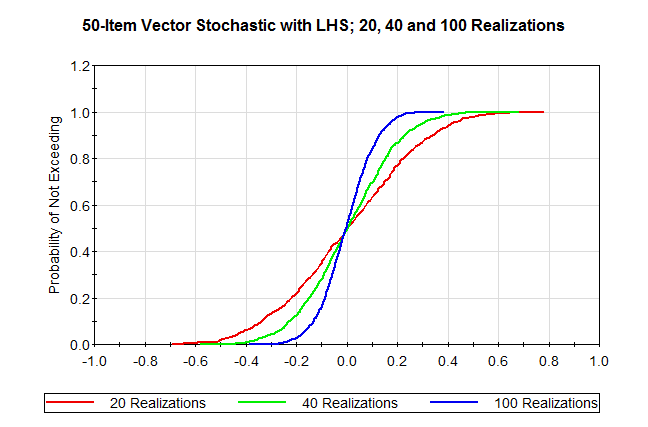
Comments
0 comments
Please sign in to leave a comment.